已弃坑😂。Andrew Ng的《AI For Everyone》视频笔记,此课程主要是AI方向扫盲。学完只能让自己对AI相关的概念不再一无所知。并不能让自己具备AI相关的技能。
第一篇
Introduction
ANI:全称artificial narrow intelligence,弱人工智能,能够完成某一特定方面的任务。例如智能音箱,自动驾驶等。
AGI:artificial general intelligence,通用人工智能(强人工智能),能够完成任何人类可以完成的事情
目前我们所接触到的AI都是ANI,离AGI的发展至少还需要很多年。
Machine Learning
监督学习:完成输入到输出的映射被称为监督学习,监督学习的数据都是有确定标注(label)的。
例如输入A是一封邮件,输出B为是否为垃圾邮件(1或0),这就是用于构建垃圾邮件筛选的AI核心思想。
对于广告推荐系统,输入一些广告信息,还有一些你的信息,然后试图预测,你是否会点击广告。
还有其他诸如音频转文字、机器翻译、基于图像雷达的自动驾驶、视觉检查等。
监督学习的飞速发展:
监督学习的概念早已存在,直到最近(大概201X年左右?)才飞速发展。主要原因是互联网和计算机的兴起,信息可以被记录再计算机里,您可以拿到的数据量有了较大增长。
对于传统的人工智能,当你输入数据更多时,它的性能会好一点,当超过一定范围,性能并不会持续增长。(有点类似于最后趋近平的对数曲线)。
但是对于现代人工智能技术以及神经网络,如果你训练的是一个稍大的神经网络,那么它的性能会比传统的人工智能性能更强。如果是一个更大规模的神经网络,那么它的性能也会变得越来越好。(最后也会趋近数据于平)
如何具有更高的性能水平:
- 拥有大数据量,即大数据,数据越多越好。
- 训练一个非常大的神经网络。
人工智能中最重要的概念就是机器学习,包括监督学习,即从输入到输出的映射,数据能使它有很好的表现。
What is data
| 房子大小 | 卧室数量 | 价格(1000$) |
|---|---|---|
| 523 | 1 | 115 |
| 645 | 1 | 150 |
| 708 | 2 | 210 |
一个数据表格,也成为数据集,比如在一个如上的表格中。
把A设定为房子大小,B设定为房子价格,多大的房子能卖多少钱,让AI系统去学习这个输入到输出的映射,也就是A到B映射。如果我们想增加额外的条件,例如房子卧室数量,这时A就是前两列数据。所以实际上,具体什么是A、B,取决于你或你的业务。
又假设,我有一定的预算,我想知道我能买多大的房子,这时A是价格,B是房子大小。
又假设,你有一组图片数据集,其中输入A代表一组不同的图像,输出B是他们的标签,某张照片是猫,某张不是猫。
PS:把猫作为一个谈论,是机器学习的惯例。
如何获取数据:
手动标注。获取一些数据后,人工手动去标注你需要的数据关键信息,例如这张图片是猫、不是猫。手动标注,是一个让你同时拥有A和B数据集的有效方法。
观察用户的行为或其他类型行为。如电商平台上,不同的物品会有不同的价格,通过纪录用户是否购买产品,就可以收集到用户名,产品的价格,购买日期,以及购买行为等数据。
例如工厂中的机器,你想要预测一台机器是否即将出现故障,那么你可以记录一个这样的数据集,机器序列号、机器的温度、机器里的压强、和机器之前是否出现过故障。可以选择机器序列号、机器的温度、机器里的压强作为输入A,机器之前是否出现过故障作为输出B。
从网站上下载或从合作伙伴那里获取。开放的互联网上有许多数据集可以免费下载,只遵守相关协议即可。
数据是重要的,但也有2点误解
- 先获取足够的数据,再构建AI团队;一旦开始收集数据,马上把数据给AI团队,AI团队可以反馈给IT团队需要哪些数据,或者需要更细致的数据。
- 只要有数据,就会有结果;通常数据多确实比数据少要好,一些决策者认为大量数据给到AI团队,就一定能发掘这些数据的价值从而获得回报。并不总是如此。一个极端的例子,一家公司收购了许多其他医药公司的数据, 理论上讲这些数据是非常有价值的。 但是几年后, 他们的工程师们还是没有了弄明白如何使用这些数据,并且真正地从中创造价值。
不要为了获取数据而过度投资,除非同时聘用一个AI团队来研究这些数据,因为他们能分析出哪些数据是有价值的。
数据是散乱的;如果数据的质量差,那么AI会学习出不准确的结果,AI团队要解决如何清理数据的问题。处理不正确的标签。
数据的类型有很多, 图片、视频和文本这些类型的数据,称之为非结构化数据,非结构化数据没有预定义的数据模型。结构化数据是高度组织和整齐格式化的数据,容易储存在一个巨大的电子表格里。处理非结构化数据的技术要比处理这些结构化数据的技术难一点。
The terminology of AI
机器学习系统的学习从输入A到输出B的映射,从而得到一个可以运行的AI系统。
数据科学:数据科学的项目结论通常是一些帮助你做上商业决定的见解,比如建造那种房屋或者是投资翻新房子。
机器学习:机器学习是一个让电脑在不被编程的情况下,就可以自己学习的研究领域,无需显示编程, 这是Arthur Samuel几十年前提出的定义。
机器学习项目通常会带出一个运行的软件,用给定的A得到输出的B。与机器学习相比,数据科学通过挖掘数据来获取见解。通常的数据科学项目的结果是一组幻灯片。
如今大型商业网站中大多都有AI系统,例如预测你是否会点击某个广告并推送。这是一个利润丰厚的AI系统。广告行业的数据科学项目,例如数据分析得到,旅游公司没有购买足够的广告,这时可以派出更多销售人员,说服他们使用更多的广告。
即使是同一家公司,也会同时有不同的机器学习项目和数据科学项目,这两项都非常具有价值。
深度学习是一种特殊的机器学习,他通过神经网络处理输入A到输入B的映射。为了区分人的大脑,也称为人工神经网络。
人工神经网络其实是类比的人的神经网络,如下图中的小圈称为人工神经元,或简称神经元。这些神经元相互传递,神经网络其实是一个大的数据方程,根据输入A,告诉如何计算B。如今的神经网络一词几乎等同于深度学习。
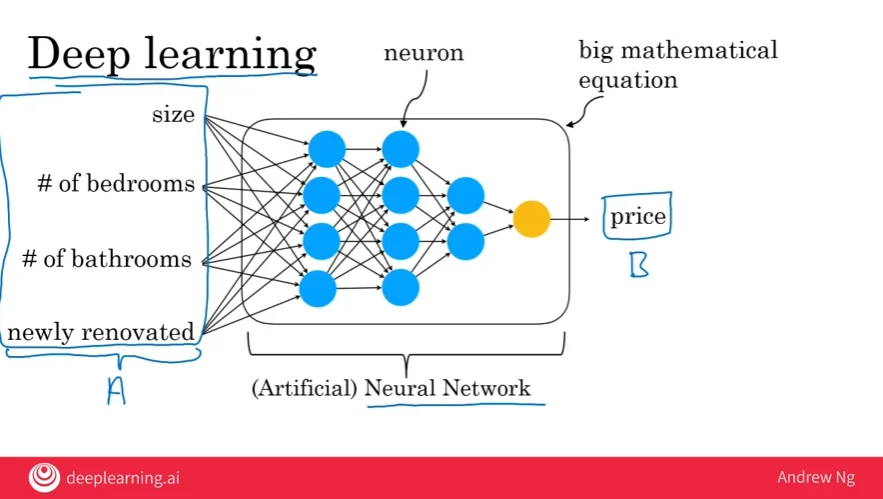
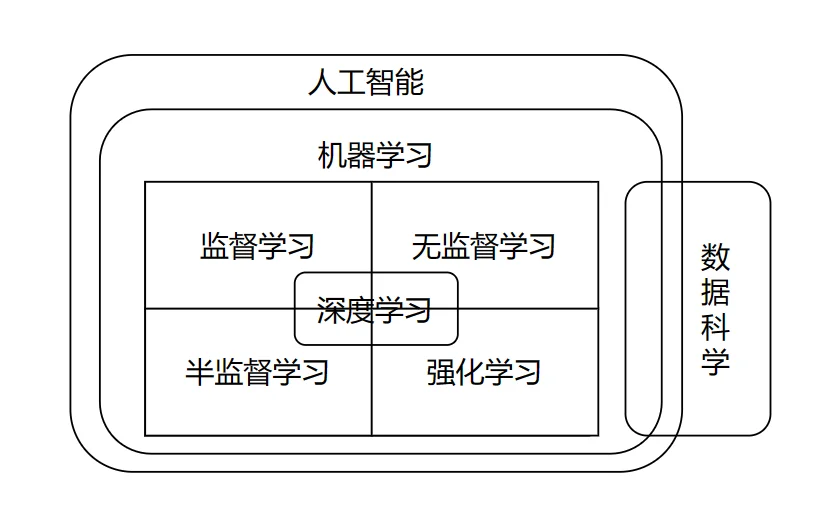
你可能也在媒体上听到其他流行语如无监督学习,强化学习,图形模型,计划,知识图表等。但是机器学习、数据科学、深度学习和神经网络也是非常重要的一部分。
What makes an AI company
如何让公司擅长人工智能?从互联网的兴起中我们知道,互联网公司并不等于web网站+公司。同样,人工智能公司并不等同于使用人工智能的公司。
- 人工智能公司擅长数据采集。也因此大型消费科技公司会有免费产品来帮助他们收集数据,并在别处产生收益。
- 人工智能公司会建立统一的数据仓库。如果有非常多个不同仓库,来分别获取数据并分析,那么几乎是不可能的。
- 人工智能公司擅长发现自动化的机会,
- 人工智能公司有很多新的岗位如MLE,和新分配任务的方式。
一个公司想要变得擅长人工智能,意味着这个公司用人工智能去做某些事情,并把它做得很好。过去很多公司例如GOOGLE花费了一定时间成为擅长人工智能的公司。但这并不是一个不可复现的过程。转型人工智能公司有以下步骤:
- 启动试点项目,从而了解人工智能,大概知道人工智能可以做什么,不可以做什么。
- 在公司内部建立一个人工智能团队,
- 提供广泛的人工智能培训,不仅要给工程师培训,还要提供给部门领导于高层管理人员。
- 制定公司的人工智能发展战略。
- 保证内外部对于人工智能发展战略沟通一致。所有的相关人员包括顾客到投资人都知道你的公司是如何在人工智能的兴起中找到前行方向的。
What machine learning can and cannot do
本章中吴恩达老师介绍的AI不能做事情,由于有一定的时间差,因此本章需要辩证看待。
通常,在开始一个人工智能项目之前,要做足够的技术调研,确保技术上是可行的。这意味着要看数据,看输入A能否完成到输出B的映射。
对于AI能做什么与不能做什么,有一个不完美的经验法则:人能够用一瞬间完成的事情,大部分都可以用监督学习来完成。例如判断周围车的距离,手机上的划痕,这些人通常耗时较短。
对于AI不能做的事情,例如让AI写一份59页的市场分析报告,因为人类还不能一瞬间写完报告。
例如,对于邮件而言,AI能对邮件进行分类,也能判断邮件是否为一封垃圾邮件。但是想让AI针对某一封邮件写出具体的内容与回信,是’目前’AI所不能做到的。AI只能生成简单的回应,例如”感谢来信,谢谢,等“,或者AI生成的是各种错乱的内容。
判断AI项目是否可行的两个经验法则:
- 机器只是学习一个简单的概念,这个概念不超过几秒,就可以得出一个正确的结论。例如分别一张图片是猫还是不是猫。观察其他车辆位置确定距离等。
- 有大量可用的数据,来学习输入A到输入B的映射。例如输入A是用户的电子邮件,输入B是用户的邮件属于什么类型,例如退款、运输、质量等。如果你有大量的A和B的电子邮件。那么该项目会更加可行。
More examples of what machine learning can and cannot do
只有我们亲眼目睹了AI成功与失败的例子,我们才能更加明确哪些AI项目能做,哪些不能做。接下来会给出更多例子。
对于自动驾驶项目,AI可以做的非常好。能通过相机、激光或者雷达等来分析他所在的位置,或者其他车的位置。这时输入A就是前方的图片或传感器数据,输出B就是其他车的位置。如今汽车行业已经收集了足够多的数据,且有相当好的算法。
现今AI无法做到的例子,例如给出一张人的手势图片,输出这个人的手势意图。这个的难点在于人的手势很多意图,不同的人的手势姿态不尽相同,因此AI通过人的手势来学习人的意图,是一个非常复杂的概念,更别说即使是人有时候也很难判断另一个人的手势的意图。
另外,这是一个对人生命安全有着重要影响的AI。一个建筑工人的手势是想让你停车还是让你继续开车,理解正确有着极大影响。这使得AI项目更加困难。
因此当今的自动驾驶汽车,有着很多的检测车辆部分的软件功能,但很少有自动驾驶团队试图依靠AI识别人类的人体姿势来安全驾驶。
使用X射线图检测肺炎的AI,输入A是X光片,输出B为是否肺炎,这是AI可以做的事情。但AI不能从解释肺炎的教科书中学习,然后检测出肺炎。但是人类可以读教科书,然后看上一小部分图像,就能对肺炎有大致的判断。AI是无法做到这一点的。
机器学习优缺点:
- AI擅长学习简单概念的事物,例如人几秒钟就可以做到的事情,以及有大量数据的事情。
AI不擅长从少量数据学习复杂概念。 - 用AI系统从未见过的新类型数据执行任务时,往往表现不佳。例如通过X射线诊断肺炎的监督学习系统中,训练时都是使用高分辨率的胸部X射线。假如将这个系统应用于其他医院,这个医院的X射线图,用户是侧躺的,由于与之前数据的巨大差异,可能结果不再准确。
一个优秀的AI团队要学会如何改善和减少这些问题。但这并不容易。如果是人,则会适应这种数据的巨大差异。