《数据结构与算法分析Java语言描述》第五章5.2与5.3节读书笔记
5.1 散列
理想的散列是只包含固定大小的数组,
通常查找是对某个数据域进行的,这部分叫做关键字(key)
每个关键字按照一定规则,均匀的映射到整个数组中。这个映射叫做散列函数
5.2 散列函数
如果输入的关键字都是整数,则一般的简单映射函数就是使用key % tableSize,直接取模。同时保证表的大小为素数,是一个好得做法。但是通常得关键字都是字符串。则散列函数有以下方法可以考虑。
5.2.1 散列函数实现方案一
把字符串得ASCII码或者Unicode码的值相加。
1 2 3 4 5 6 7 public static int hash (String key, int tableSize) { int hashVal = 0 ; for (int i = 0 ; i < key.length(); i++) { hashVal += key.charAt(i); } return hashVal % tableSize; }
以上函数,实现简单,计算方便,但是如果表很大,则表的的高位利用率较低,导致冲突率增大。
Java的散列表如HashMap等只会进行扩容,并不会缩小数组,如果采用ASCII码方案,HashMap的数组扩容后,使用不满,可能导致上述的情况发生。
5.2.2 散列函数实现方案二
假设key至少有三个字符,只考察前三个字符,将ASCII码乘起来得到一个整数
1 2 3 public static int hash2 (String key, int tableSize) { return (key.charAt(0 ) + 27 * key.charAt(1 ) + 27 * 27 * key.charAt(2 )) % tableSize; }
值27表示ASCII字符加一个空格,第一个字符就是本来的值,第二个字符是27 * 原值,第三个字符是27*27*原值。假设在完全随机的情况下,则3个字符的组合有19683种组合的可能。大于tableSize = 10007,则可以均匀分布。但是单词是有一定规律的,并不是均匀分布的。根据统计单词的前三个字母只有2851种组合,所以这种方法还是不适合。
Java的HashMap的数组最大为2 30 2^{30} 2 3 0 2 30 2^{30} 2 3 0
5.2.3 散列函数实现方案三
所有字符参与计算,计算∑ i = 0 k e y S i z e − 1 K e y [ i ] ∗ 3 7 i \sum_{i=0}^{keySize - 1} Key[i]* 37^i ∑ i = 0 k e y S i z e − 1 K e y [ i ] ∗ 3 7 i
根据horner法则计算一个37的多项式:例如:h k = k 0 + 37 k 1 + 3 7 2 k 2 h_k = k_0 + 37k_1 + 37^{2}k_2 h k = k 0 + 3 7 k 1 + 3 7 2 k 2 h k = ( ( k 2 ) ∗ 37 + k 1 ) ∗ 37 + k 0 h_k = ((k_2) * 37 + k_1)*37 + k_0 h k = ( ( k 2 ) ∗ 3 7 + k 1 ) ∗ 3 7 + k 0
1 2 3 4 5 6 7 8 9 10 11 12 public static int hash3 (String key, int tableSize) { int hashVal = 0 ; for (int i = 0 ; i < key.length(); i++) { hashVal += 37 * hashVal + key.charAt(i); } hashVal %= tableSize; if (hashVal < 0 ) { hashVal += tableSize; } return hashVal; }
改散列函数基本可用,且实现简单。但是如果关键字特别长,则计算耗时特别多,一个行之有效的方法是只取奇数位置的字符串进行计算。不能只取部分的原因是,例如地址之类的,前半部分都是一样的。
5.3 哈希冲突之分离链接法
将散列到数组同一个位置上的所有元素都保留到同一个列表中。并连接到数组对应下标上的位置(数组中并不存储元素,只存储于列表)
5.3.1 具体操作
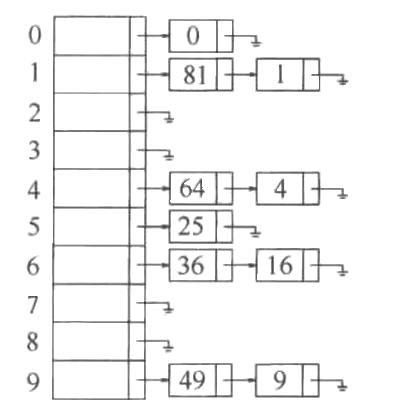
为简化操作,这里假设关键字是前10个完全平方数,并假设散列函数是hash(x) = x mod 10(表的大小不是素数(是10),这里是为简化操作)。
Jdk8的hashMap从之前的头插法改为尾插法,是为了解决多线程下,hashMap扩容时rehash时导致的链表成环的问题(并发请用correntHashMap)。jdk8及之后改为了尾插法。
本次实现的对象,必须实现equals方法于hashCode方法。hashCode用来计算判断应该链在哪条链表下,equals用于在hsah冲突后判断是否时同一个对象。如下是一个实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 public class SeparateChainingHashTable <AnyType> { private static final int DEFAULT_TABLE_SIZE = 101 ; private List<AnyType>[] theLists; private int currentSize; public SeparateChainingHashTable () { this (DEFAULT_TABLE_SIZE); } public SeparateChainingHashTable (int size) { theLists = new LinkedList [nextPrime(size)]; for (int i = 0 ; i < theLists.length; i++) { theLists[i] = new LinkedList <>(); } } public int myHash (AnyType x) { int hashVal = x.hashCode(); hashVal %= theLists.length; if (hashVal < 0 ) { hashVal += theLists.length; } return hashVal; } private void reHash () { List<AnyType>[] oldLists = theLists; theLists = new List [nextPrime(2 * theLists.length)]; for (int j = 0 ; j < theLists.length; j++) { theLists[j] = new LinkedList <>(); } currentSize = 0 ; for (int i = 0 ; i < oldLists.length; i++) { for (AnyType item : oldLists[i]) { insert(item); } } } public void insert (AnyType x) { List<AnyType> whichList = theLists[myHash(x)]; if (!whichList.contains(x)) { whichList.add(x); currentSize += 1 ; if (currentSize > theLists.length) { reHash(); } } } public boolean contains (AnyType x) { List<AnyType> whichList = theLists[myHash(x)]; return whichList.contains(x); } public void remove (AnyType x) { List<AnyType> whichList = theLists[myHash(x)]; if (whichList.contains(x)) { whichList.remove(x); currentSize--; } } public void makeEmpty () { for (int i = 0 ; i < theLists.length; i++) { theLists[i].clear(); } currentSize = 0 ; } }
装填因子λ \lambda λ
上例的装填因子λ \lambda λ λ \lambda λ λ / 2 \lambda / 2 λ / 2 λ \lambda λ